世界の大規模言語モデル(LLM)市場:提供別(ソフトウェア(ドメイン固有LLM、汎用LLM)、サービス)

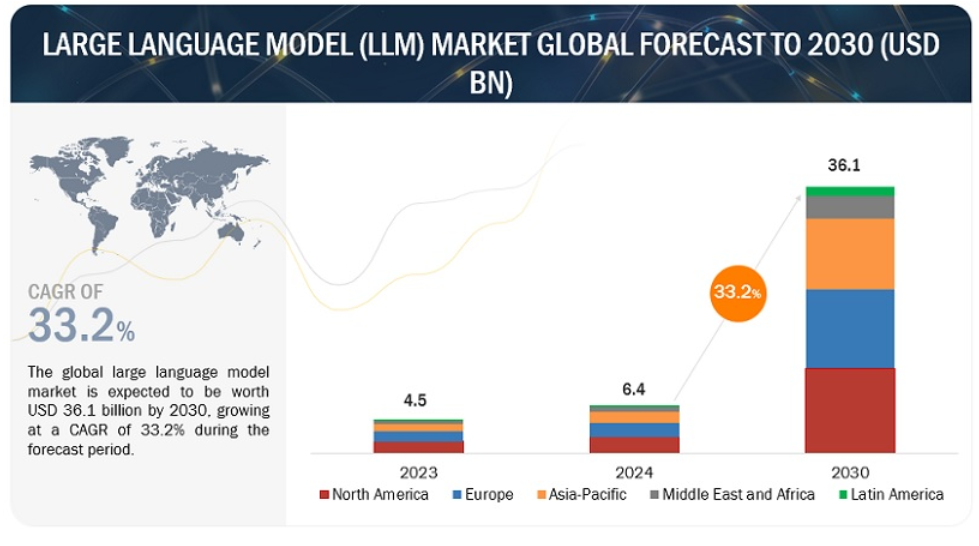
大規模言語モデル(LLM)市場は現在力強い成長を遂げており、市場規模の大幅な拡大が予測されている。市場規模は、2024年の64億米ドルから2030年には361億米ドルに拡大し、予測期間中の年平均成長率(CAGR)は33.2%に達すると予測されている。この驚異的な成長率は、様々な業界において高度な自然言語処理(NLP)能力に対する需要が高まっているためである。LLMは、テキスト生成、感情分析、言語翻訳、コンテンツ要約などのタスクで卓越した能力を発揮しており、顧客体験の向上、コンテンツ作成の自動化、データ主導の意思決定プロセスの推進に役立つ貴重なツールとなっている。さらに、クラウド・コンピューティングの登場と強力なコンピューティング・リソースの利用可能性により、これらの複雑なモデルの大規模な訓練と展開が容易になった。企業がAIや機械学習技術を活用して競争力を高めようと努力する中、大規模言語モデルの採用が急増し、市場の急成長に拍車をかけている。
大規模言語モデル市場の技術ロードマップ
大規模言語モデル市場のレポートでは、短期的および長期的な発展に関する洞察を含む技術ロードマップをカバーしています。
短期(1-5年):
専用ハードウェアアクセラレータが可能にする兆パラメータモデル
多様なタスクにわたる教師なしマルチタスク学習
新しい知識でモデルを更新する継続的学習
ロバストなアライメントと制御技術(ディベート、再帰的報酬モデリング)
エッジコンピューティングとプライバシーのためのオンデバイスLLMデプロイメント
長期的(5年以上):
人間レベルの言語理解と生成
言語、視覚、音声をシームレスに統合する統合マルチモーダルモデル
根拠のある常識的推論と世界知識
学習データを超えた新たな言語能力
オープンエンドな会話能力を持つ一般的なAIアシスタント
大規模言語モデル(LLM)市場
市場動向
推進要因:自動コンテンツ作成とキュレーションの需要の高まり
コンテンツの自動作成とキュレーションに対する需要の高まりが、大規模言語モデル(LLM)市場の成長を後押ししている。LLMは、自然言語生成機能を活用して人間のようなテキストをかつてない規模で作成することで、魅力的なソリューションを提供します。これらのモデルは、マーケティング資料や製品説明からニュース記事やクリエイティブなストーリーまで、特定のオーディエンスやコンテキストに合わせた幅広いコンテンツを生成することができます。LLMはコンテンツのキュレーションと要約を得意とし、企業が膨大なデータソースから効率的に洞察を抽出することを可能にします。この能力は、研究、ジャーナリズム、ナレッジ・マネジメントなど、情報の取捨選択と統合が重要な業界にとって非常に貴重である。
制約:大規模な言語モデルの学習と推論最適化の高コスト
大規模言語モデル(LLM)に関連する学習と推論にかかる高コストは、LLMの普及と市場成長の大きな妨げとなる。LLMは膨大な計算リソースを必要とし、GPT-3のような最大規模のモデルは数千の高性能GPUで学習するため、数百万ドルものコストがかかります。さらに、LLMは膨大な量の多様で高品質な学習データを必要とするため、その取得と管理には多大なリソースとコストがかかります。GPT-3のトレーニングデータの取得と処理にかかるコストは、500万米ドルから1200万米ドルに上ると見積もられている。さらに、訓練と推論過程でのエネルギー消費は非常に大きく、多額の運用コストがかかる。
機会: 知識発見と管理におけるLLMへの需要の高まり
知識発見と管理におけるLLMの採用の増加は、LLM市場に大きな機会をもたらしている。組織が膨大な量のデータを生成するにつれ、効率的に洞察を抽出し、情報を管理する必要性が極めて重要になっている。LLMは自然言語処理における高度な機能を提供し、データの分類、感情分析、傾向の特定といったタスクの自動化を可能にする。例えば、ヘルスケア業界では、LLMは医学文献や患者記録の分析を支援し、治療効果や疾病管理における新たな傾向を特定することができます。金融機関では、コンプライアンスや投資の意思決定のために、膨大な規制文書や市場レポートを選別するためにLLMを活用することができます。
課題 高いメモリ要件による計算効率の低下
LLMに必要なメモリ容量が大きいと計算効率が低下し、市場の成長にとって大きな課題となる。これらのモデルがより複雑で高度になるにつれて、膨大な数のパラメータとデータ表現を保存するために、より大きなメモリ容量が必要となります。その結果、LLMの導入と実行は資源集約的なものとなり、堅牢なハードウェア・インフラと膨大な計算リソースが必要となる。小規模な組織や予算が限られている組織は、必要なハードウェアのアップグレードやクラウド・コンピューティング・サービスを利用する余裕がないため、これがボトルネックになります。また、必要なメモリ量が多いと、処理時間が長くなり、モデル学習が遅くなるため、リアルタイム・アプリケーションや応答性の妨げになります。
2024年から2030年にかけて、ドメイン特化型LLMが最も速い成長率を記録する。
ドメイン特化型LLMは、その特化した焦点と、さまざまな業界にわたって的を絞ったソリューションを提供する能力により、市場で急速な成長を遂げている。ヘルスケア、金融、法律など特定の領域に特化したデータでトレーニングされたこれらのモデルは、一般的なLLMと比較して優れたパフォーマンスを提供する。そのため、その分野に特化した言語のニュアンスを理解することができ、より正確で文脈に即した出力が得られます。ドメインに特化したLLMは、微調整に必要なリソースやデータが少なくて済むことが多く、費用対効果が高く効率的なビジネス・ソリューションとなります。LLMはゼロショット、ワンショット、数ショットの学習シナリオに優れており、最小限の学習データで知識を一般化し、新しいタスクに素早く適応することができます。
モダリティ別では、テキスト・セグメントが2024年に最高シェアを獲得
テキスト・モダリティは、そのユビキタス性と業界横断的な汎用性により、LLM市場を支配すると予想される。ソーシャルメディア、電子メール、文書などのソースから得られるテキストデータの急激な増加に伴い、テキストに特化したLLMの需要が急増している。これらのモデルは、センチメント分析、コンテンツ生成、文書分類などのタスクに優れており、多様なビジネスニーズに対応しています。さらに、テキストベースのLLMは拡張性、解釈可能性、費用対効果を提供するため、企業にとって非常に魅力的です。
モデルサイズ別では、10億~100億パラメータセグメントが2024年に最大の市場シェアを占める予定
10億~100億パラメータ・セグメントは、モデルの複雑さと計算効率の最適なバランスにより、LLM市場をリードしている。LLaMA Pro(83億パラメータ)、GAIA-1(90億パラメータ)、BlenderBot 2.0(94億パラメータ)など、このサイズ範囲のモデルは、メモリと処理要件の点で管理可能でありながら、高性能を提供することで心を打つ。自然言語の理解、生成、翻訳など様々なタスクに優れており、様々な業界にアピールしている。また、これらのモデルは、スケーラビリティ、手頃な価格、多用途性を提供し、あらゆる規模の企業が利用できるようになっている。
アーキテクチャ別では、オートエンコードLLMが予測期間中に最も急成長する見込みです。
オートエンコードLLMは、そのユニークなアーキテクチャと汎用性の高いアプリケーションにより、市場で急成長を遂げるだろう。オートエンコーダーフレームワークを活用したこれらのモデルは、テキスト再構成、特徴抽出、教師なし学習などのタスクに優れています。生のデータから意味のある表現を学習する能力により、データの前処理や次元削減において非常に効果的です。さらに、自動エンコードLLMはプライバシーとデータセキュリティを強化し、機密情報を扱う企業にとって魅力的です。
アプリケーション別では、言語翻訳とローカリゼーションが予測期間中に最も高い成長率を示すと予想されている。
言語翻訳とローカライゼーションは、グローバル化による需要の増加により、LLM市場で最も急成長するアプリケーション・セグメントとして注目される見込みです。企業はグローバルに事業展開しようとするため、さまざまな言語で正確かつ文化的に適切な翻訳が求められます。LLMは、多様な言語ニーズに対応し、効率的で正確な翻訳サービスを提供することで、この分野を得意としています。この分野の成長は、機械学習技術の進歩によってさらに促進され、LLMは最小限の人的介入で高品質の翻訳を提供することができます。
エンドユーザー別では、メディア&エンターテインメント分野が2024年に最大の市場シェアを占めるだろう。
メディア&エンターテインメント分野は、コンテンツ作成、キュレーション、パーソナライゼーションに大きく依存しているため、2024年のLLM市場で最大の市場シェアを占めると推定される。LLMは、コンテンツ生成、レコメンデーション・システム、センチメント分析などのタスクを自動化し、ユーザー・エンゲージメントと満足度を高めるという、これまでにない機能を提供する。LLMは、コンテンツの効率的なモデレーションを促進し、規制基準へのコンプライアンスを確保し、ブランドの評判を守ります。ストリーミング・プラットフォーム、ソーシャルメディア、デジタル・コンテンツの普及に伴い、コンテンツ配信と視聴者とのインタラクションを最適化するLLM搭載ソリューションの需要は急増の一途をたどっている。
地域別では、アジア太平洋地域が予測期間中に最も速い成長率を記録する。
アジア太平洋地域は、大規模言語モデル市場において2024年から2030年の間に最も急成長する市場として際立つことが予想される。同地域の多様な言語環境は、各国で話されている多数の言語に対応するための高度な言語処理技術を必要としている。LLMは、多言語のコンテンツを理解、生成、翻訳する機能を提供するため、このような状況において高い関連性を持つ。例えば、インドのAIスタートアップであるSarvam社は、2024年2月にOpenHathi-Hi-v0.1と呼ばれる最初のLLMをリリースした。このLLMは、Meta社のオープンソースLlama2-7Bアーキテクチャ上に構築されており、インド系言語向けにGPT-3.5と同等のパフォーマンスを実現している。
さらに、この地域の政府はAIの研究開発に多額の投資を行っており、LLMの技術革新と導入に適した環境を育成している。例えば、中国ではすでに10億を超えるパラメータを持つ70以上のLLMがリリースされており、毎日さらに多くの申請が行われている。米国の輸出規制により、LLMトレーニング用の高性能なNvidia GPUにアクセスすることが困難なため、中国はAIスタートアップを支援する措置を実施している。上海を含むいくつかの都市政府は、LLMのトレーニング費用を補助するため、AIスタートアップに「コンピューティング・バウチャー」を提供している。
主要企業
大規模言語モデル・ソリューションおよびサービス・プロバイダーは、新製品発売、製品アップグレード、提携・契約、事業拡大、M&Aなど、さまざまな種類の有機的・無機的成長戦略を実施し、市場での提供を強化している。大規模言語モデル市場の主要企業には、グーグル(米国)、OpenAI(米国)、Anthropic(米国)、Meta(米国)、マイクロソフト(米国)のほか、Mosaic ML(米国)、Stability AI(英国)、LightOn(フランス)、Cohere(カナダ)、Turing(米国)などの中小企業や新興企業がある。
この調査レポートは、大規模言語モデル市場を、提供、アーキテクチャ、モダリティ、モデルサイズ、用途、エンドユーザー、地域に基づいて分類しています。
オファリング別
ソフトウェア
ソフトウェア, タイプ別
汎用LLM
ドメイン特化型LLM
ゼロショット
ワンショット
少数ショット
多言語LLM
タスク別LLM
ソフトウェア、ソースコード別
オープンソースLLM
クローズドソースLLM
ソフトウェア、デプロイメント・モード別
オンプレミス
クラウド
サービス
コンサルティング
LLM開発
インテグレーション
LLM微調整
完全微調整
検索補強型ジェネレーション(RAG)
アダプタベースのパラメータ効率的チューニング
LLMベースのアプリ開発
迅速なエンジニアリング
サポートとメンテナンス
アーキテクチャ別
自己回帰言語モデル
単頭自己回帰言語モデル
多頭自己回帰言語モデル
自動エンコーディング言語モデル
バニラ自己符号化言語モデル
最適化自己符号化言語モデル
ハイブリッド言語モデル
テキスト対テキスト言語モデル
プリトレーニング・ファインチューニング・モデル
モダリティ別
テキスト
コード
画像
ビデオ
モデルサイズ別
10億パラメータ以下
10億~100億パラメータ
100億~500億パラメータ
500億~1000億パラメータ
1,000億~2,000億パラメータ
2,000億~5,000億 パラメータ
500億パラメータ以上
アプリケーション別
情報検索
言語翻訳とローカリゼーション
多言語翻訳
ローカリゼーションサービス
コンテンツ生成とキュレーション
自動ジャーナリズムと記事執筆
クリエイティブライティング
コード生成
カスタマーサービス自動化
チャットボットとバーチャルアシスタント
セールスとマーケティングの自動化
パーソナライズされたレコメンデーション
データ分析とBi
センチメント分析
ビジネスレポートと市場分析
その他のアプリケーション
エンドユーザー別
IT/ITeS
ヘルスケア&ライフサイエンス
法律事務所
BFSI
製造業
教育
小売
メディア&エンターテイメント
その他エンドユーザー
地域別
北米
米国
カナダ
欧州
英国
ドイツ
フランス
その他のヨーロッパ
アジア太平洋
中国
インド
日本
韓国
その他のアジア太平洋地域
中東・アフリカ
GCC
南アフリカ
トルコ
その他の中東・アフリカ
中南米
ブラジル
メキシコ
その他のラテンアメリカ
2024年2月、グーグルは注目すべきLLMの発表を行い、大幅な進化を遂げたGemini 1.5を発表した。検索大手のグーグルは、さまざまなモダリティにまたがる長いコンテキストの理解を備えた最新のAIモデル、Gemini 1.5を発表した。グーグルはまた、軽量オープンウェイトモデルの新ファミリーであるGemmaも発表した。Gemma 2BとGemma 7Bから始まるこれらの新しいモデルは、「Geminiにインスパイアされた」もので、商用および研究用に利用できる。
2024年2月、キンドリルは責任ある生成AIソリューションを開発するため、グーグル・クラウドとの提携拡大を発表した。このパートナーシップは、Googleの最先端の大規模言語モデル(LLM)であるGeminiを含むGoogle Cloudの社内AI機能と、Kyndrylの専門知識およびマネージドサービスを結合し、顧客のために生成的AIソリューションを開発・展開することに重点を置く。
2024年1月、キャップジェミニとAWSは、企業におけるジェネレーティブAIの幅広い導入を可能にするため、戦略的協業を拡大しました。この協業を通じて、キャップジェミニとAWSは、コスト、規模、信頼などの課題を克服しながら、顧客がジェネレーティブAIの導入によるビジネス価値を実現できるよう支援することに注力している。
2023年12月、マイクロソフトは大規模言語モデル(LLM)を活用した自動データ探索システム、InsightPilotを発表した。この革新的なシステムは、データ探索プロセスを簡素化するために特別に設計されている。InsightPilotには、データ探索を簡素化するために綿密に設計された一連の分析アクションが組み込まれている。
2023年12月、グーグルはVideoPoetと名付けられた前例のない大規模言語モデル(LLM)を発表した。この画期的なモデルは、これまでのLLMでは見られなかった動画生成機能を導入している。
2023年12月、アクセル・シュプリンガーとOpenAIは、人工知能(AI)時代の独立ジャーナリズムを強化するためのグローバル・パートナーシップを発表した。このイニシアティブは、様々なトピックに関する最新の権威あるコンテンツを追加することで、ユーザーのChatGPT体験を豊かにし、OpenAIの製品に貢献する出版社の役割を明確に評価する。
2023年11月、OpenAIはGPT-4の次世代モデルであるGPT-4 Turboの発売を発表しました。GPT-4 Turboはより高性能で、2023年4月までの世界の出来事の知識を持っている。128kのコンテキスト・ウィンドウを持ち、1つのプロンプトに300ページ以上のテキストを入力できる。
2023年10月、デルとメタは、オープンソースAI「ラマ2」をオンプレミスの企業ユーザーに提供するために提携した。デルは、Dell Validated Design for Generative AIハードウェアのラインナップと、オンプレミス展開向けのジェネレーティブAIソリューションに、Llama 2モデルのサポートを追加すると発表した。
【目次】
1 はじめに (ページ – 56)
1.1 調査目的
1.2 市場の定義
1.2.1 包含と除外
1.3 市場範囲
1.3.1 市場セグメンテーション
1.3.2 対象地域
1.3.3 考慮した年数
1.4 考慮した通貨
表1 米ドル為替レート、2020-2023年
1.5 利害関係者
1.5.1 景気後退の影響
2 調査方法(ページ数 – 61)
2.1 調査データ
図1 大規模言語モデル市場:調査デザイン
2.1.1 二次データ
2.1.2 一次データ
表2 一次インタビュー
2.1.2.1 一次プロフィールの内訳
図2 主要プロフィールの内訳(企業タイプ、呼称、地域別
2.1.2.2 主要な業界洞察
図3 専門家による主な洞察
2.2 市場規模の推定
図4 大規模言語モデル市場:トップダウンアプローチとボトムアップアプローチ
2.2.1 トップダウンアプローチ
2.2.2 ボトムアップアプローチ
図5 アプローチ1(ボトムアップ、サプライサイド): 大規模言語モデルのソリューション/サービスベンダーからの収益
図6 アプローチ2(ボトムアップ、サプライサイド): 大規模言語モデルのすべてのソリューション/サービスからの総収入
図7 アプローチ3(ボトムアップ、サプライサイド): すべてのソリューション/サービスと対応するソースからの市場推定
図8 アプローチ4(ボトムアップ、需要側): 人工知能支出全体における大規模言語モデルのシェア
2.3 データの三角測量
図9 データの三角測量
2.4 市場予測
表3 要因分析
2.5 調査の前提
表4 調査の前提
2.6 調査の限界
図10 調査の限界
2.7 景気後退の市場への影響
表5 景気後退が世界市場に与える影響
3 主要業績(ページ数 – 73)
表6 世界の大規模言語モデルの市場規模と成長率、2020~2023年(百万米ドル、前年比)
表7 世界の市場規模と成長率、2024-2030年(百万米ドル、前年比)
図11 2024年に市場規模を拡大するソフトウェア・セグメント
図 12 予測期間中、ソフトウェアタイプ別では汎用 llms が支配的なセグメントとなる
図 13 2024 年にはクローズドソース型 llms 分野(ソフトウェアソースコード別)が市場を支配する
図 14 クラウドが予測期間中に急成長する展開モード
図 15 2024 年にはサービス別 llm 開発セグメントが最大の市場シェアを占める
図 16 自動符号化llmsアーキテクチャ分野は2024~2030年に最も速い成長率を記録する
図17 2024年に最大の市場シェアを占めるモダリティ別テキスト・セグメント
図18 10億~100億パラメータセグメント(モデルサイズ別)、2024年に最大市場シェアに
図19 予測期間中に最も成長するアプリケーションは言語翻訳とローカリゼーション分野
図 20 ヘルスケア&ライフサイエンス分野が予測期間中に最も高い成長率を示す
図21 2024年から2030年にかけて最も高い成長率を記録するのはアジア太平洋地域
4 PREMIUM INSIGHTS (ページ数 – 81)
4.1 大規模言語モデル市場における企業の魅力的な機会
図22 多様な産業における洗練されたNLPアプリケーションの需要増加が極めて重要な成長促進要因に
4.2 市場:上位3つのアプリケーション
図 23 情報検索アプリケーション分野が予測期間中に最も高い成長率を占める
4.3 北米:市場:サービス別、エンドユーザー別
図24 2024年にはソフトウェアとメディア&エンターテインメントが北米の最大株主となる
4.4 地域別市場
図 25 2024 年には北米が最大の市場シェアを占める
5 市場概要と業界動向(ページ – 84)
5.1 はじめに
5.2 市場ダイナミクス
図 26 推進要因、阻害要因、機会、課題 大規模言語モデル市場
5.2.1 推進要因
5.2.1.1 大規模データセットの増加
図 27 世界で生成・消費されるデータ量、2010年~2023年(ゼタバイト)
5.2.1.2 深層学習アルゴリズムの進歩
図28 モデルサイズの急増に伴い急速にスケールするLLMの性能、2018年~2023年(億パラメータ)
5.2.1.3 人間と機械のコミュニケーション強化のニーズ
図29 チャットボットによる会話への適応が進むユーザー(2021年対2022年
5.2.1.4 コンテンツの自動作成とキュレーションの需要の高まり
図30 企業規模を問わない大規模言語モデルのユースケース(2022年
5.2.2 阻害要因
5.2.2.1 モデル学習と推論最適化のコストが高い
図31 様々なgpt-3ベースの大規模言語モデルの100万パラメータ当たりの学習コスト
5.2.2.2 データの偏りと品質への懸念
5.2.2.3 説明可能性と解釈可能性における透明性の欠如
5.2.3 機会
5.2.3.1 LLMを使用した言語翻訳とローカリゼーションの強化
5.2.3.2 LLMを使った感情認識と感情分析
図32 人間の認知スキルにおける著名なLLMのスコア(2022年
5.2.3.3 知識発見と管理におけるLLMの需要の高まり
5.2.4 課題
5.2.4.1 高い推論待ち時間
5.2.4.2 巨大なメモリ要件による計算効率の低下
図33 いくつかの著名なLLMSの計算要件(テラフロップ)
5.2.4.3 モデルの性能と完全性の維持
図34 gpt-4における3ヶ月以内のモデル・ドリフト(2023年3月と2023年6月の比較)
5.3 大規模言語モデル市場の進化
図35 市場の進化
5.4 大型言語モデル: ソフトウェア層
5.4.1 エンベッディング層
5.4.2 フィードフォワード層
5.4.3 リカレント層
5.4.4 注意層
5.5 バリューチェーン分析
図36 市場:バリューチェーン分析
表8 市場:バリューチェーン分析
5.6 エコシステム分析/市場マップ
表9 市場:エコシステム
図 37 大規模言語モデル市場マップ 主要プレーヤー
5.6.1 大規模言語モデルソフトウェアプロバイダー
5.6.1.1 LLM APIプロバイダー
5.6.1.2 ベクトルデータベースプロバイダー
5.6.1.3 LLMフレームワークプロバイダー
5.6.1.4 音声合成プロバイダー
5.6.1.5 LLMモニタリングツールプロバイダ
5.6.2 大規模言語モデルサービスプロバイダー
5.6.2.1 コンピュートプラットフォームプロバイダ
5.6.2.2 モデルハブ
5.6.2.3 ファインチューニング/カスタムモデル学習フレームワーク
5.6.2.4 モニタリング/オブザーバビリティ・プラットフォーム・プロバイダー
5.6.2.5 ホスティングサービスプロバイダー
5.6.3 エンドユーザー
5.6.4 政府・規制機関
5.7 投資環境と資金調達シナリオ
図 38 資金調達額と資金調達ラウンド別の主要ローン開発企業(2017~2024 年)(百万米ドル
図 39 最も評価の高いLLM開発企業、2023年(10億米ドル)
図40 大規模言語モデル運用(llmops)への投資(カテゴリー別)、2023年(百万米ドル
図41 大型言語モデル市場の取引件数と取引額(2021年第1四半期~2023年第3四半期)(百万米ドル
5.8 ケーススタディ分析
5.8.1 BFSI
5.8.1.1 生成AIを活用したEdger Financeの投資情報収集・分析の高速化
5.8.2 メディア&エンターテイメント
5.8.2.1 Ben Groupはメディア&エンターテイメント業界の分散型デジタル世界に革命を起こした
5.8.3 ヘルスケア&ライフサイエンス
5.8.3.1 サマーヘルスがOpenAIで小児科医の診察を再構築
5.8.4 IT/ITES
5.8.4.1 Oxide AIがIBM watsonx.aiを試験的に導入し、金融における投資情報過多を解決
5.8.5 法律事務所
5.8.5.1 ManzはDeepsetクラウドを活用し、セマンティック検索によって法務調査の労力を大幅に削減した。
5.9 テクノロジー分析
5.9.1 主要テクノロジー
5.9.1.1 自然言語処理(NLP)
5.9.1.2 ディープラーニング
5.9.1.3 トランスフォーマーアーキテクチャ
5.9.1.4 注意メカニズム
5.9.1.5 トランスファー学習
5.9.2 隣接技術
5.9.2.1 音声認識
5.9.2.2 コンピュータビジョン
5.9.2.3 強化学習
5.9.2.4 知識グラフ
5.9.3 補完技術
5.9.3.1 量子コンピューティング
5.9.3.2 説明可能なAI
5.9.3.3 エッジコンピューティング
5.9.3.4 ブロックチェーン
5.10 規制の状況
5.10.1 規制機関、政府機関、その他の組織
表10 北米:規制機関、政府機関、その他の組織
表 11 欧州: 規制機関、政府機関、その他の組織
表12 アジア太平洋: 規制機関、政府機関、その他の団体
表13 中東・アフリカ:規制機関、政府機関、その他の団体
表14 ラテンアメリカ:規制機関、政府機関、その他の団体
5.10.2 規制: 大規模言語モデル市場
5.10.2.1 北米
5.10.2.1.1 カリフォルニア州消費者プライバシー法(CCPA)
5.10.2.1.2 カナダの自動意思決定に関する指令
5.10.2.1.3 AIと自動意思決定システム(AADS)条例(ニューヨーク市)
5.10.2.2 欧州
5.10.2.2.1 一般データ保護規則(GDPR)
5.10.2.2 欧州連合の人工知能法(AIA)
5.10.2.2.3 欧州委員会による信頼できるAIのための倫理ガイドライン
5.10.2.3 アジア太平洋地域
5.10.2.3.1 個人情報保護法(PIPL)-中国
5.10.2.3.2 人工知能倫理ガイドライン – 日本
5.10.2.3.3 AI戦略とガバナンスの枠組み – オーストラリア
5.10.2.4 中東・アフリカ
5.10.2.4.1 UAE AI規制と倫理ガイドライン
5.10.2.4.2 南アフリカの個人情報保護法(POPIA)
5.10.2.4.3 エジプトのデータ保護法
5.10.2.5 ラテンアメリカ
5.10.2.5.1 ブラジル – 一般データ保護法(LGPD)
5.10.2.5.2 メキシコ – 民間団体が保有する個人データの保護に関する連邦法(LFPDPPP)
5.10.2.5.3 アルゼンチン – 個人データ保護法(PDPL)
5.11 特許分析
5.11.1 方法論
5.11.2 出願特許(文書タイプ別
表15 出願された特許、2013-2023年
5.11.3 技術革新と特許出願
図42 過去10年間に取得された特許数(2013-2023年
5.11.3.1 大規模言語モデル市場における上位特許所有者
図43 市場における出願人上位10社、2013-2023年
表16 市場における特許所有者トップ20、2013-2023年
表17 2022-2023年市場における少数の特許リスト
図44 付与された特許の地域分析、2013-2023年
5.12 価格分析
5.12.1 主要企業の平均販売価格動向(ソフトウェアタイプ別
図45 主要プレイヤーの平均販売価格動向(ソフトウェアタイプ別
表18 主要プレイヤーの平均販売価格動向(ソフトウェアタイプ別
5.12.2 オファリング別の指標価格分析
表19 大規模言語モデルソリューションの価格水準(提供製品別
5.13 貿易分析
5.13.1 コンピューターソフトウェアの輸出シナリオ
図 46 コンピュータソフトウェアの輸出額(主要国別)、2015~2022 年(10 億米ドル
5.13.2 コンピュータソフトウェアの輸入シナリオ
図47 コンピューターソフトウェアの輸入額(主要国別)、2015~2022年(10億米ドル
5.14 主要会議・イベント
表20 大型言語モデル市場:会議・イベントの詳細リスト(2024~2025年
5.15 ポーターの5つの力分析
表21 ポーターの5つの力が市場に与える影響
図 48 ポーターの5つの力分析:市場
5.15.1 新規参入の脅威
5.15.2 代替品の脅威
5.15.3 供給者の交渉力
5.15.4 買い手の交渉力
5.15.5 競争相手の強さ
5.16 技術ロードマップ
図49 大規模言語モデル市場の技術ロードマップ
5.17 ビジネスモデル
図50 大型言語モデル:ビジネスモデル
5.17.1 ソフトウェアベンダーモデル
5.17.2 クラウドAPIアクセスモデル
5.17.3 カスタムトレーニング/微調整モデル
5.17.4 マーケットプレイス/取引所モデル
5.18 顧客のビジネスに影響を与えるトレンド/混乱
5.18.1 大規模言語モデルプロバイダーの収益シフトと新たな収益ポケット
図 51 顧客のビジネスに影響を与えるトレンド/混乱
5.19 主要ステークホルダーと購買基準
5.19.1 購入プロセスにおける主要ステークホルダー
図 52 主要エンドユーザーの購買プロセスにおける利害関係者の影響力
表 22 主要エンドユーザーの購買プロセスにおける関係者の影響力
5.19.2 購入基準
図53 エンドユーザー上位3社の主な購買基準
表 23 上位 3 エンドユーザーの主な購買基準
6 大規模言語モデル市場, 製品別 (ページ – 144)
6.1 はじめに
6.1.1 オファリング 市場牽引要因
図 54 2024 年に市場シェアを拡大するソフトウェア分野
表 24:オファリング別市場(2020~2023 年)(百万米ドル
表25 オファリング別市場:2024-2030年(百万米ドル)
6.2 ソフトウェア、タイプ別
図 55 2024~2030 年にかけてドメイン別 llms が最も急成長するセグメント
表 26:ソフトウェアタイプ別市場(2020~2023 年)(百万米ドル
表 27:ソフトウェアタイプ別市場(2024~2030 年)(百万米ドル
6.2.1 汎用LLMS
6.2.1.1 汎用LLMの高い汎用性と迅速な適応性により、複数のユースケースへの普及が加速
表 28 汎用 LLM: 大規模言語モデル市場、地域別、2020~2023年(百万米ドル)
表 29 汎用 LLM: 市場、地域別、2024~2030年(百万米ドル)
6.2.2 ドメイン特化型 llms
6.2.2.1 ドメイン特化型 LLM の採用は、各業界に特化した LLM を求める組織の切迫したニーズが原動力になる
6.2.2.2 ゼロショット
表 30 ゼロショットドメイン特化型 LLM: 市場, 地域別, 2020-2023 (百万米ドル)
表 31 ゼロショットドメイン特化型 llms: 市場、地域別、2024~2030 年(百万米ドル)
6.2.2.3 ワンショット
表 32 ワンショットドメイン特化型 llms: 市場:地域別、2020-2023 年(百万米ドル)
表 33 ワンショットドメイン特化型 llms: 市場:地域別、2024~2030 年(百万米ドル)
6.2.2.4 ツーショット
表 34 少数ショットのドメイン特化型 llms: 市場:地域別、2020~2023 年(百万米ドル)
表 35 少数ショットドメイン特化型 llms: 市場、地域別、2024-2030 年(百万米ドル)
6.2.3 多言語 llms
6.2.3.1 グローバル化の進展と包括性の推進がシームレスな多言語言語処理能力への需要を喚起
表 36 多言語 llms: 大規模言語モデル市場、地域別、2020年~2023年(百万米ドル)
表 37 多言語 llms: 市場、地域別、2024-2030年(百万米ドル)
6.2.4 タスク別llms
6.2.4.1 ミッションクリティカルなアプリケーション向けのタスク指向言語モデルにおける高精度・高精度の需要がタスク特化型LLMの成長を牽引
表 38 タスク特化型 LLM: 市場, 地域別, 2020-2023 (百万米ドル)
表 39 タスク特化型 LLM: 市場:地域別、2024~2030 年(百万米ドル)
6.3 ソフトウェア、ソースコード別
図 56 2024 年にはクローズドソース型 llms 分野が最大シェアを占める
表 40:ソフトウェアソースコード別市場(2020~2023 年)(百万米ドル
表 41:ソフトウェアソースコード別市場(2024~2030 年)(百万米ドル
6.3.1 オープンソースのLLMS
6.3.1.1 強力なオープンソース LLM モデルが利用可能であり、オープンソースコミュニティの協力的 な性質と相まって、オープンソース LLM の採用と成長を促進する。
表 42 オープンソース LLM: 地域別市場、2020-2023 年(百万米ドル)
表 43 オープンソース LLM: 市場:地域別、2024-2030 年(百万米ドル)
6.3.2 クローズドソース型 llms
6.3.2.1 クローズドソース型LLMは、カスタマイズされたドメイン固有のAIソリューションのニーズと、独占的アクセスや独自の優位性への欲求によって牽引される
表 44 クローズドソース型 LLM: 市場, 地域別, 2020-2023 (百万米ドル)
表 45 クローズドソース型 llms: 市場:地域別、2024~2030 年(百万米ドル)
6.4 ソフトウェア、導入形態別
図 57 2024 年にはクラウドセグメントがより大きな市場シェアを占める
表 46:ソフトウェア展開モード別市場(2020~2023 年)(百万米ドル
表47:ソフトウェア展開モード別市場(2024~2030年)(百万米ドル
6.4.1 クラウド
6.4.1.1 スケーラブルで簡単にアクセスできるLLM APIへの需要の高まりがクラウドベースのLLMの成長を促進
表 48 クラウド:地域別市場、2020~2023 年(百万米ドル)
表 49 クラウド:地域別市場、2024-2030 年(百万米ドル)
6.4.2 オンプレミス
6.4.2.1 厳格なデータプライバシーと機密領域のデータ処理に対する企業のニーズが、ローカライズされた配備と制御を実現するオンプレミス型LLMの成長を促す
表 50 オンプレミス: 大規模言語モデル市場、地域別、2020-2023年(百万米ドル)
表51 オンプレミス: 市場、地域別、2024-2030年(百万米ドル)
6.5 サービス
図58 LLMファインチューニングサービスが2024~2030年に市場で最も高い成長率を記録
表 52:サービス別市場、2020~2023年(百万米ドル)
表53 サービス別市場:2024~2030年(百万米ドル)
6.5.1 コンサルティング
6.5.1.1 LLMの導入と実施戦略に関する専門家の指導に対する需要の高まりがコンサルティングサービス分野を牽引
表 54 コンサルティング 市場, 地域別, 2020-2023 (百万米ドル)
表55 コンサルティング: コンサルティング:地域別市場、2024-2030年(百万米ドル)
6.5.2 LM開発
6.5.2.1 LLM開発サービスは、特定のユースケースや業種に合わせたカスタムLLMへのニーズの高まりに後押しされる
表 56 LLM 開発: 市場, 地域別, 2020-2023 (百万米ドル)
表 57 LLM開発: LLM開発:地域別市場、2024-2030年(百万米ドル)
6.5.3 統合
6.5.3.1 既存のソフトウェアエコシステムとワークフローにLLMをシームレスに組み込む必要性が、統合サービスの需要を高める
表 58:統合:市場(地域別)、2020~2023 年(百万米ドル
表59 統合:地域別市場、2024~2030年(百万米ドル)
6.5.4 LLMの微調整
6.5.4.1 ドメイン固有およびタスク固有のLLM最適化がLLM微調整サービス市場の拡大に寄与
6.5.4.2 完全ファインチューニング
表60 フルファインチューニング:地域別市場、2020~2023年(百万米ドル)
表61 フルファインチューニング:大規模言語モデル市場、地域別、2024年~2030年(百万米ドル)
6.5.4.3 検索補強型生成(RAG)
表62 検索補強世代:市場、地域別、2020年~2023年(百万米ドル)
表63 検索補強世代:市場:地域別、2024~2030年(百万米ドル)
6.5.4.4 アダプタベースのパラメータ効率チューニング
表64 アダプタベースのパラメータ効率チューニング:市場:地域別、2020~2023年(百万米ドル)
表65 アダプタベースのパラメータ効率チューニング:市場:地域別、2024~2030年(百万米ドル)
6.5.5 LLM ベースのアプリ開発
6.5.5.1 様々な分野でLLMを利用したアプリケーションの人気が高まっていることから、LLMを利用したアプリ開発サービスの採用が増加傾向にある。
表 66 LLM ベースのアプリ開発: 市場、地域別、2020年~2023年(百万米ドル)
表67 LLMを活用したアプリ開発: 市場:地域別、2024~2030年(百万米ドル)
6.5.6 プロンプトエンジニアリング
6.5.6.1 プロンプトエンジニアリングサービスは、LLMのパフォーマンスを最適化するための効果的なプロンプト設計の重要性により、急成長が見込まれている。
表 68 プロンプトエンジニアリング 市場, 地域別, 2020-2023 (百万米ドル)
表 69 プロンプトエンジニアリング: プロンプトエンジニアリング:地域別市場、2024~2030 年(百万米ドル)
6.5.7 サポート&メンテナンス
6.5.7.1 LLMモデルの更新、モニタリング、長期サポートの継続的ニーズがサポート&保守サービスの採用を促進
表 70 サポート&メンテナンス:地域別市場、2020~2023 年(百万米ドル)
表71 サポート&メンテナンス:地域別市場:2024-2030年(百万米ドル)
7 大言語モデル市場:アーキテクチャ別(ページ – 182)
7.1 はじめに
7.1.1 アーキテクチャ:市場促進要因
図 59 自動符号化 llms は予測期間中に最も高い成長率を示す
表 72:アーキテクチャ別市場(2020~2023 年)(百万米ドル
表73 アーキテクチャ別市場:2024~2030年(百万米ドル)
7.2 自己回帰言語モデル
7.2.1 複雑な言語パターンと文脈内の依存関係を捉える自己回帰言語モデル
表 74 自己回帰言語モデル 市場、地域別、2020年~2023年(百万米ドル)
表 75 自己回帰言語モデル: 市場、地域別、2024-2030 年(百万米ドル)
7.2.2 シングルヘッド自己回帰言語モデル
7.2.3 マルチヘッド自己回帰言語モデル
7.3 自動符号化言語モデル
7.3.1 下流タスクの微調整まで拡張するAELMSは、産業界と学界での普及につながる
表 76 自動符号化言語モデル: 市場, 地域別, 2020-2023 (百万米ドル)
表 77 自動エンコード言語モデル: 市場:地域別、2024~2030年(百万米ドル)
7.3.2 バニラ自動符号化言語モデル
7.3.3 最適化自動エンコーディング言語モデル
7.4 ハイブリッド言語モデル
7.4.1 自己回帰コンポーネントと自己符号化コンポーネントを統合することで、文脈理解と生成能力を必要とするタスクで優れた能力を発揮できるようにする。
表 78 ハイブリッド言語モデル: 市場, 地域別, 2020-2023 (百万米ドル)
表 79 ハイブリッド言語モデル: 地域別市場、2024-2030年(百万米ドル)
7.4.2 テキスト対テキスト言語モデル
7.4.3 事前学習-微調整モデル
…
【本レポートのお問い合わせ先】
www.marketreport.jp/contact
レポートコード:TC 8977
- 胎児牛血清の世界及び日本市場2026年:種類別(北米産、南米アメリカ産、オーストラリア産)
- 世界のメシル酸シルデナフィル市場
- ロボティクス市場レポート:製品タイプ(産業、サービス)、地域別 2024-2032
- スマートラベル市場:グローバル予測2025年-2031年
- 自動遮光溶接ヘルメットの世界市場2025:種類別(パッシブ溶接ヘルメット、自動遮光溶接ヘルメット)、用途別分析
- 海底増圧装置の世界及び日本市場2026年:種類別(大型、中小型)
- 過酸化ケタールの世界及び日本市場2026年:種類別(1,1-ジ(tert-ブチルペルオキシ)-3,3,5-トリメチルシクロヘキサン、1,1-ジ(tert-ブチルペルオキシ)-シクロヘキサン、2,2-ジ(tert-ブチルペルオキシ)-ブタン、メチルエチルケトン過酸化物)
- コンビニエンスストアのグローバル市場規模は2024年に6,593億2,000万ドル、2031年までにCAGR 6.51%で拡大する見通し
- ESGソフトウェアのグローバル市場規模調査:タイプ別(環境管理ソフトウェア、社会管理ソフトウェア、ガバナンス管理ソフトウェア、その他)、組織規模別(中小企業、大企業)、導入形態別(オンプレミス、クラウド)、業種別、地域別予測:2022-2032年
- 世界の香料市場(2025 – 2032):種類別、形態別、供給源別、用途別、地域別分析レポート
- TPU黄変防止剤の世界及び日本市場2026年:種類別(紫外線吸収剤、ヒンダードアミン系光安定剤、酸化防止剤)
- 世界のテトラフルオロエタンベータスルトン市場